





Target của bài viết: Những bạn muốn trở thành Senior backend developer hoặc mong muốn tìm hiểu CQRS là gì.
Một số thuật ngữ mình dùng trong bài viết các bạn có thể search thêm cụ Google để nắm hơn:
- High availability: Một hệ thống website có tính sẵn sàng cao. Hoạt động liên tục 24/7 trong mọi điều kiện, kể cả khi có sự cố xảy ra.
- High consistency: Tính nhất quán về dữ liệu, tất cả request của user đều thấy được dữ liệu mới nhất nếu nó được update.
- Trade-off: Đánh đổi khi thiết kế hệ thống lớn
GIỚI THIỆU MỘT CHÚT TRƯỚC KHI TÌM HIỂU CQRS LÀ GÌ
Bài viết này rất dài, có thể sẽ mất của bạn vài chục phút đến vài giờ để đọc và hiểu nội dung. Nhưng nó sẽ rất đáng nếu bạn bỏ ra từng ấy thời gian vì những gì bạn sẽ thu lại được. Mình đã cố gắng viết nó ra thì bây giờ đến lượt bạn, cố gắng đọc hiểu nó và góp ý thêm cho mình nha.
Let’s go!
Nếu bạn muốn tìm hiểu sâu về backend thì đọc thêm bài này của mình.
Loose Coupling quan trọng như thế nào trong hệ thống backend | Cybozu Vietnam Tech Sharing
ĐIỂM XUẤT PHÁT: MÔ HÌNH TRUYỀN THỐNG VÀ THÁCH THỨC
Trước khi bắt đầu khám phá CQRS là gì, hãy xem xét một ứng dụng ví dụ sử dụng mô hình truyền thống (ví dụ MVC). Chúng ta sẽ sử dụng một dự án Rest API service với Java và Spring Boot framework.
MÔ HÌNH TRUYỀN THỐNG (VÍ DỤ SỬ DỤNG MVC)
Ở mức đơn giản, chúng ta thường có một cấu trúc thư mục quen thuộc với các tầng như Controller, Service, Repository và Model.
Trước khi vào bài thì mình có một yêu cầu nhỏ. Các bạn phải từng làm qua một framework backend rồi nha. Ví dụ NestJs, Laravel, .Net MVC hay gì cũng được. Hoặc các bạn đã nắm được về kiến trúc MVC. Hiểu thế nào là view, model, controller, repository, service, …
Trong bài viết này, mình sẽ lấy ví dụ với Java (Spring boot framework). Các bạn cũng đừng lo lắng. Vì nếu các bạn nắm được MVC rồi hoặc 1 trong các backend framework. Thì chúng ta cũng không cần quan tâm tới ngôn ngữ mình thể hiện trong bài viết nữa. Đừng quá phụ thuộc vào chúng, hãy cố gắng nắm được nội dung và hiểu nó.
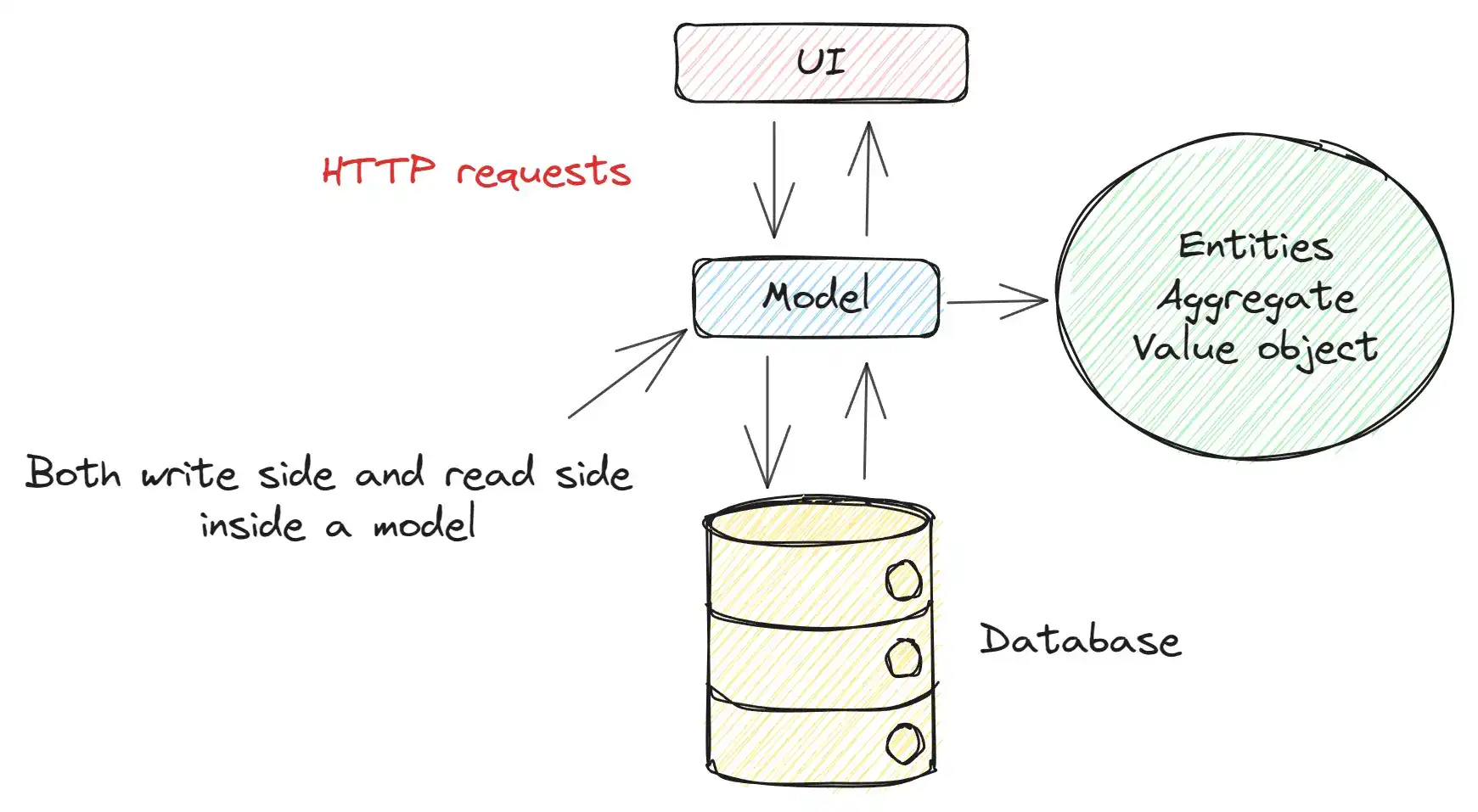
Chúng ta sẽ tập trung vào tầng Model trước! Nếu bạn đã làm việc với hệ thống Backend thì bạn cũng đã thao tác rất nhiều với các Model.
À, từ đây đến hết bài viết, mình sẽ chia các HTTP request thành 2 loại:
- Write side – hay còn gọi là Command side: Bao gồm tất cả các request chỉnh sửa vào database (POST, PUT, DELETE request)
- Read side – hay còn gọi là Query side: Bao gồm tất cả các request dùng để lấy dữ liệu từ database (GET request)
Lưu ý là mình sẽ sử dụng 2 từ read side và write side trong xuyên suốt bài viết.
ĐI VÀO CODE MỘT CHÚT
Ok, mình sẽ lấy ví dụ triển khai một ứng dụng web báo điện tử. Ví dụ như VnExpress hay 24h, …
Giả sử mình có một model Article. Và khi các bạn thực hiện các API như createArticle, updateArticle, deleteArticle, getArticleById, getAll, … thì bạn vẫn cứ phải thao tác với model Article.
Ví dụ vào code nha. Lưu ý là chúng ta chỉ quan tâm hàm create thôi nha.
Chúng ta có một cấu trúc thư mục cực kì quen thuộc với hầu hết các bạn.
com.lenhatthanh.blog/
|-- controller/
| |-- ArticleController.java
| `-- ...
|-- service/
| |-- ArticleService.java
| `-- ...
|-- repository/
| |-- ArticleRepository.java
| `-- ...
`-- model/
|-- ArticleEntity.java
`-- ...Các bạn có thể đọc lướt qua cũng được. Vì các bạn đã quá quen thuộc với kiểu viết API backend như vậy.
// ArticleController.java
@RestController
@RequestMapping("/api/v1/articles")
@AllArgsConstructor
public class ArticleController {
private ArticleServiceInterface articleService;
@PostMapping
@ResponseStatus(HttpStatus.CREATED)
public void create(@RequestBody ArticleDto article) {
articleService.create(article);
}
// Một số API khác như update, delete, getAll, getById, getByAuthor, ....
}// ArticleService.java
@AllArgsConstructor
@Service
public class ArticleService {
private ArticleRepository articleRepository;
private UserRepository userRepository;
public void create(ArticleDto articleRequest) {
Optional<User> user
= userRepository.findById(articleRequest.getUserId());
if (user.isEmpty()) {
throw new UserNotFoundException("APPLICATION-ERROR-0001");
}
Article article = new Article(
UUID.randomUUID().toString(),
articleRequest.getTitle(),
articleRequest.getContent(),
user.get().getId(),
articleRequest.getSummary(),
articleRequest.getThumbnail(),
articleRequest.getSlug(),
// ...
);
articleRepository.save(article);
}
// Một số API khác như update, delete, getAll, getById, getByAuthor, ....
}// ArticleRepository
@Repository
public interface ArticleRepository
extends JpaRepository<ArticleEntity, String> {
}Repository trong Spring Boot thì khá lạ. Vì bạn chẳng thấy các method CRUD (create, read, update, delete) đâu cả. Vì ở đây Repository đang được kế thừa JpaRepository của Spring Data JPA trong Spring Boot. Và trong interface đó đã có hết toàn bộ những method CRUD và mở rộng hơn.
Bây giờ chúng ta sẽ đi qua model chính trong ứng dụng đơn giản này.
// ArticleEntity.java
@AllArgsConstructor
@NoArgsConstructor
@Data
@Builder
@Entity
@Table(name="articles")
public class ArticleEntity implements Serializable {
@Serial
private static final long serialVersionUID = 6009937215357249661L;
@Id
@Column(nullable = false, unique = true, length = 100)
private String id;
@Column(nullable = false)
private String title;
@Column(columnDefinition = "TEXT", length = 20000)
private String content;
@ManyToOne(fetch = FetchType.LAZY)
private UserEntity user;
@Column(columnDefinition = "TEXT", length = 1000)
private String summary;
@Column(nullable = false, unique = true)
private String thumbnail;
@Column(nullable = false, unique = true, length = 100)
private String slug;
// Một số properties khác nữa
// ...
// Bên dưới là business logic
// Ví dụ: Slug chỉ được phép chứa các kí tự a-z, A-Z và dấu _
}Ở trên đây, model Article của chúng ta làm tới 2 nhiệm vụ là mapping với một ORM để thao tác trực tiếp với database table. Và nhiệm vụ thứ 2 là lưu trữ state (trạng thái) của hệ thống. Ở đây là lưu trữ state của một Article trong vòng đời của một request.
Vấn đề ở đây là gì?
CODEBASE LỚN, KHÓ BẢO TRÌ NẾU KHÔNG DÙNG CQRS
Model trong một ứng dụng enterprise sẽ làm khá nhiều nhiệm vụ:
- Lưu trữ trạng thái (như mình nói ở trên)
- Mapping với database (cũng giống mình nói ở trên)
- Cái tiếp theo là thông thường trong model sẽ chứa business logic. Mà business logic của những model lớn thường sẽ rất phức tạp. Về thuật ngữ business logic (hay domain logic, hay nghiệp vụ) thì các bạn có thể search google để biết nha. Cái này cũng khá là dễ hiểu.
Rõ ràng chúng ta chỉ có một model Article. Vì vậy các thao tác read side và write side đều phải thao tác qua model này.
Nghĩa là một model sẽ phải chứa tất cả business logic cho cả CRUD. Và khi ứng dụng càng lớn, business logic càng nhiều. Và thay đổi càng nhiều thì sẽ khiến cho model càng ngày càng phức tạp. Kể cả các tầng khác như Controller, Service, hay Repository cũng sẽ phức tạp hơn rất nhiều. Codebase lúc này sẽ phình to ra và dẫn tới việc bảo trì và mở rộng khó khăn hơn.
ĐẶC BIỆT LÀ KHI BẠN SỬ DỤNG ORM ĐỂ TƯƠNG TÁC VỚI DATABASE
-
Write side: Khi bạn thực hiện các API write side (create, update, delete) thì bạn dùng ORM để mapping database khá là đơn giản. Ví dụ create thì lưu 1 lần xuống toàn bộ thông tin của entity (ứng dụng lớn thì lưu cả cụm aggregate). Vì vậy thao tác về mặt code sẽ khá tường minh và đơn giản (cho dù có liên kết n-n hay 1-n, …).
-
Read side: Câu này mình sẽ nhắc nhiều trong bài viết: Ở read side thì số lượng use case (có thể coi 1 use case là 1 API đi cho dễ) sẽ vô cùng nhiều và đặc biệt khó dự đoán được. Ví dụ một số use case
- Lấy danh sách bài viết cùng với summary để hiển thị ở khu vực recommend hoặc homepage (chỉ lấy title, thumbnail, summary)
- Lấy danh sách bài viết của một tác giả (chỉ lấy title, thumbnail, summary)
- Lấy danh sách bài viết trong tháng này.
- Lấy danh sách bài viết có lượng truy cập cao trong (ngày, tuần, tháng, …)
- Lấy danh sách bài viết theo category, kết hợp với ngày tháng, tác giả, …
- v/v (còn rất nhiều use case khác nữa)
CHO NÊN
Khi bạn dùng ORM đối với rất nhiều use case như vậy và tương tác với chỉ một entity Article thì toang. Business logic trong model này sẽ trở nên phức tạp. Chưa nói là phải join tùm lum bảng (kết hợp nhiều entity). Và chưa nói tiếp tới vụ dư thừa dữ liệu và phức tạp khi join các bảng mà dùng ORM.
Và code base ở các file service, controller, repository cũng sẽ trở nên phức tạp theo. Vì có nhiều use case mà như mình có nói hồi nảy.
Và khi đó, đôi khi chúng ta phải thực hiện query thuần cho những API bên read side.
DƯ THỪA DỮ LIỆU
Trước khi mình nói về vấn đề dư thừa dữ liệu. Thì mình muốn nói thêm một ý khá quan trọng:
Write side chúng ta thường tao tác với hầu hết các field (trường dữ liệu) trong model (entity). Ví dụ tạo một article thì chúng ta sẽ thao tác gần như tất cả các field trong một entity. Nhưng read side thì không như vậy, đôi khi chỉ thao tác với một vài trường dữ liệu trong một entity. Hoặc kết hợp nhiều entity với nhau (join nhiều bảng một lần) – như mình nói ở các use case read site ở trên.
Ngoài ra thì hầu hết các hệ thống web application, các request read side thường chiếm phần lớn trong hệ thống. Ví dụ một trang thương mại điện tử, người bán hàng tạo một sản phầm và publish nó (write side). Và người bán chỉ tạo một lần đó thôi, còn lại hầu hết các request từ user khác đến sản phẩm đó là read side, ví dụ xem chi tiết sản phẩm, sản phẩm tương tự, search, …
Cũng vì lý do read side và write side đều được xử lý thông qua một model duy nhất. Nên đôi khi sẽ làm chúng ta bị dư thừa dữ liệu, đặc biệt ở read side.
MÌNH LẤY VÍ DỤ
- Giả sử ArticleEntity ở trên có khoảng vài chục trường dữ liệu (ở trên thì mình chỉ lấy ví dụ có vài trường dữ liệu thôi). Thì khi chúng ta thực hiện tạo mới một article, thì rõ ràng khá bình thường, chúng ta sẽ lưu cả entity xuống database (cùng với đó là thêm thông tin userId để biết đang của tác giả nào).
- Nhưng khi ở read side, giả chúng ta chỉ lấy vài trường dữ liệu để hiển thị. Nhưng chúng ta phải query hết toàn bộ dữ liệu rồi map vào entity. Và rồi loại bỏ dữ liệu dư thừa rồi trả ra view cho user. Và như mình nói thì ở read side rất đa dạng các kiểu get dữ liệu lên. Mà mỗi lần get dữ liệu lên lại phải get hết thông qua entity thì bị dư thừa (còn tạo nhiều model khác ứng với mỗi trường hợp get dữ liệu thì codebase sẽ loạn lên). Hoặc là kiểu join nhiều bảng, ráp một ít dữ liệu của entity này và một ít dữ liệu của entity khác. Tình trạng dư thừa dữ liệu khi get data lên (rồi mapping thông qua ORM) là rất nhiều.
KHẢ NĂNG CHỊU TẢI KÉM
Chúng ta chỉ thao tác với một database duy nhất nên việc khả năng chịu tải kém lá đúng. Đột nhiên một lúc nào đó, hàng triệu request read side tới hệ thống thì hệ thống sẽ tạch ngay. Cho dù bạn có scale hệ thống bằng cách như tăng cấu hình phần cứng, load balancing, … thì request cao vẫn sẽ tạch, vì database connection lúc này rất nhiều. Database lúc này sẽ trở thành điểm bottlenecks (nút thắt cổ chai).
Ở ngay đây (hơi ngoài lề một chút), nhiều bạn sẽ cho rằng, chúng ta sẽ dùng một cache server để handle.
Và thông thường các bạn chưa có kinh nghiệm sẽ triển khai một ứng dụng với Cache database như thế này.
- Ở read side, khi có request tới cache, nếu không có trong cache (miss cache) thì chui xuống database để lấy thông tin. Cách này, cũng tạm được, sẽ giảm tải được khá nhiều cho database, nhưng ở ngoài hệ thống lớn, người ta không làm như vậy.
- Lý do là vì: khi hàng triệu use truy xuất tới một endpoint bị miss cache và đều chui xuống database thì trường hợp này cũng sẽ tạch. Ví dụ mấy sàn thương mại điện tử vào dịp 9/9 hay 10/10 tổ chức flash sale. Thì các trường hợp hàng triệu user truy cập vào một endpoint là điều bình thường.
Cho nên triển khai như vậy sẽ không hợp lý đối với một hệ thống real world.
TẢN MẠN – CQRS LÀ CÁI GÌ
CQRS (Command Query Responsibility Segregation) là một mô hình kiến trúc phát triển ứng dụng. Nổi tiếng với khả năng tách biệt quyền truy vấn (Query) và quyền thực hiện lệnh (Command).
Nói cách dễ hiểu hơn! Thì read side và write side được tách biệt hoàn toàn không còn dính tới nhau nữa. Khác hoàn toàn với cách xử lý truyền thống ở trên.
Và bên write side người ta gọi là command, bên read side người ta gọi là query.
Biết được CQRS là gì rồi, tiếp thôi nào!
LỢI ÍCH CỦA CQRS LÀ GÌ?
- Tăng khả năng mở rộng: CQRS cho phép các command và query được xử lý riêng biệt. Điều này có thể giúp tăng khả năng mở rộng của hệ thống.
- Tăng hiệu suất: CQRS có thể giúp tăng hiệu suất của hệ thống bằng cách cho phép các command và query được xử lý theo cách tối ưu nhất cho từng loại.
- Tăng khả năng bảo trì: CQRS có thể giúp tăng khả năng bảo trì của hệ thống bằng cách tách biệt các command và query. Điều này có thể giúp các anh dev dễ dàng sửa đổi hoặc nâng cấp hệ thống hơn.
- Tăng khả năng tái sử dụng: CQRS có thể giúp tăng khả năng tái sử dụng của hệ thống bằng cách tách biệt các command và query. Điều này có thể giúp các dev dễ dàng reuse lại các thành phần trong hệ thống
Những lợi ích ở trên đây mình chỉ tóm tắt thôi.
Để biết chi tiết hơn về lợi ích của CQRS là cái gì. Thì chúng ta đi sâu hơn một chút nhé.
ĐƠN GIẢN HOÁ CODEBASE GIÚP HỆ THỐNG DỄ BẢO TRÌ VÀ MỞ RỘNG
Nếu doanh nghiệp nghèo chỉ có tiền thuê được một server database. Thì chúng ta vẫn sẽ áp dụng CQRS để đơn giản hoá codebase trước.
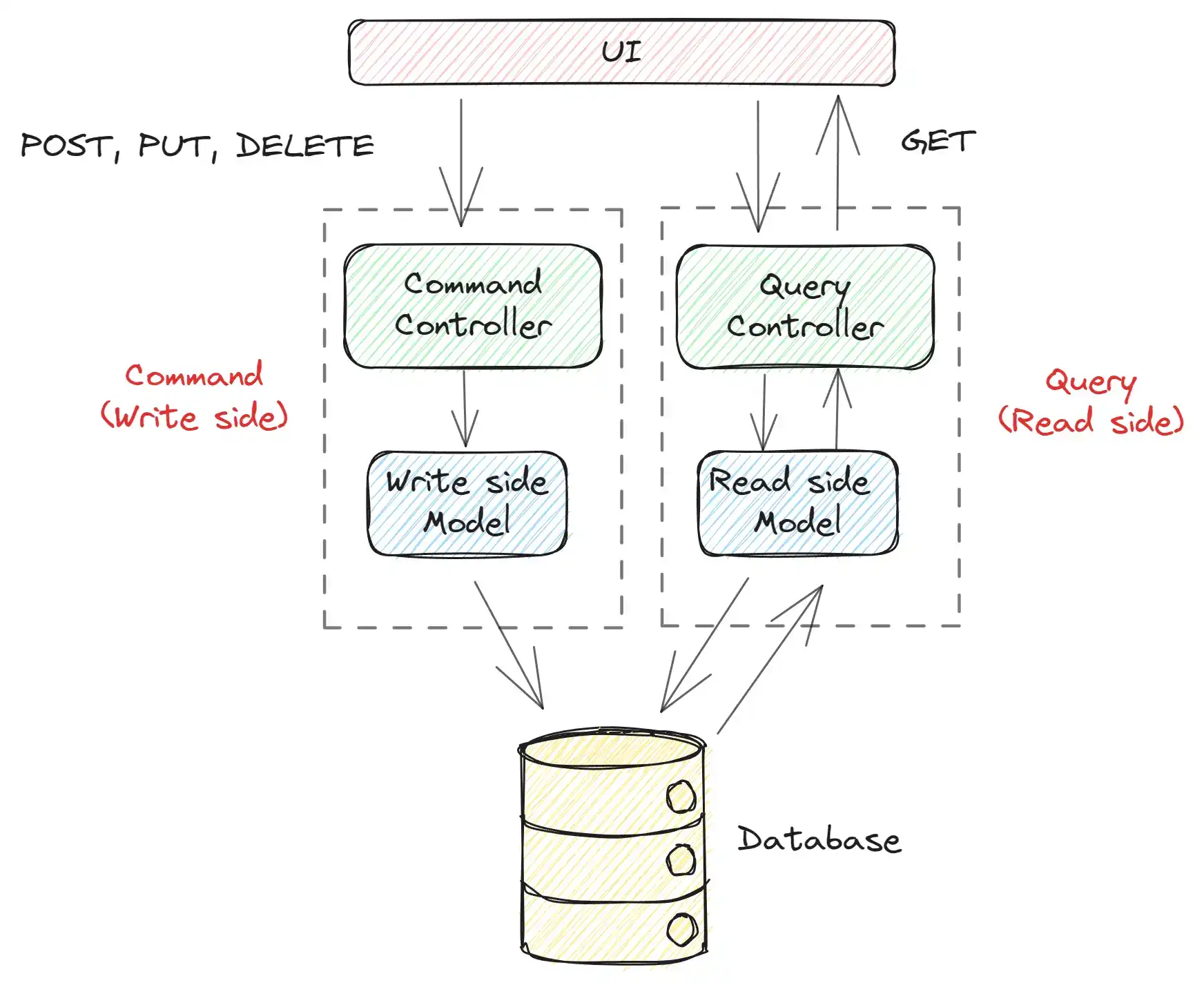
Bây giờ chúng ta sẽ tổ chức cấu trúc thư mục lại áp dụng CQRS nha. Tổ chức cấu trúc thư mục là hoàn toàn linh hoạt đối với từng project và từng team. Nên đối với CQRS sẽ có khá nhiều cách tổ chức cấu trúc thư mục. Mình thì muốn tách ra hoàn toàn thành 2 phần khác nhau.
Các bạn có thể tách ra thành 2 repository (github) hoàn toàn tách biệt luôn.
com.lenhatthanh.blog.command/
|-- controller/
| |-- ArticleController.java (create, update, delete)
| `-- ...
|-- service/
| |-- ArticleService.java
| `-- ...
|-- repository/
| |-- ArticleRepository.java
| `-- ...
`-- model/
|-- ArticleEntity.java
`-- ...com.lenhatthanh.blog.query/
|-- controller/
| |-- ArticleController.java (all get requests)
| `-- ...
|-- service/
| |-- ArticleService.java
| `-- ...
|-- repository/
| |-- ArticleRepository.java (ở đây có thể sử dụng query thuần)
| `-- ...
`-- model/
|-- Các Model tương ứng với từng use case
`-- ...Khi apply CQRS, số lượng file có thể sẽ tăng lên, nhưng đó không phải là vấn đề. Vì lúc này code base đã được tách ra thành 2 phần riêng biệt. Code base lúc này rất dễ bảo trì và mở rộng.
TỐI ƯU HÓA CODE BASE WRITE SIDE
- Đương nhiên rồi! chúng ta sẽ sử dụng ORM ở write side là quá tuyệt vời (dễ code, dễ bảo trì và cực kì tường minh).
- Và đối với ứng dụng enterprise, chúng ta có thể dùng Domain Driven Design để có thể tập trung toàn bộ business phức tạp lại một chổ (ở core domain). Để ứng dụng có thể dễ dàng mở rộng về mặt codebase khi business thay đổi hoặc tăng lên phức tạp. Ngoài ra chúng ta có thể kết hợp thêm Clean Architecture để có một cấu trúc code base tốt hơn. Nhưng không phải bạ đâu cũng dùng nha các bạn
- Ngoài ra ORM còn giúp chúng ta nhiều thứ hơn như về ngăn chặn các vấn đề security (như SQL injection, …).
TỐI ƯU HÓA CODE BASE READ SIDE
- Như mình đã nói thì số lượng request và use case ở đây cực kì phức tạp. Nên chúng ta có thể dùng query thuần (không dùng ORM) ở phần read side (trong trường hợp ứng dụng của bạn chỉ có một database ví dụ MySQL). Khi sử dụng query thuần thì code sẽ đở phức tạp đi rất nhiều so với dùng ORM ở read side. Bạn có thể thử dùng ORM và join nhiều bảng cùng với mỗi bảng thì lấy một ít dữ liệu sẽ thấy ngay vấn đề.
Sau khi tối ưu về mặt codebase như trên thì chúng ta sẽ có một thiết kế như sau:
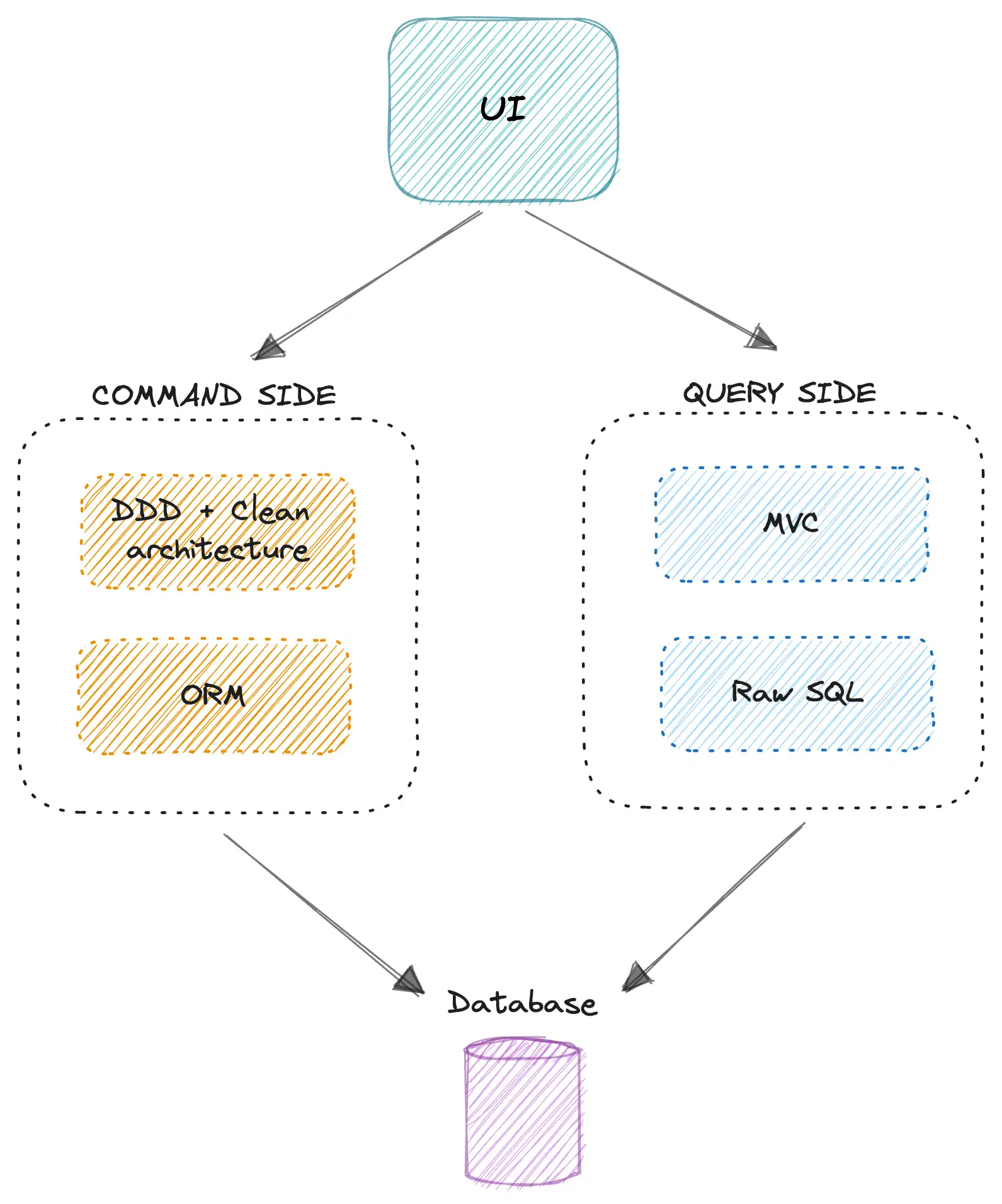
Nhưng trên thực tế. Nếu đã apply CQRS thì ít ai chỉ tối ưu về mặt codebase mà không tối ưu về mặt database và server. Vì tối ưu về khả năng chịu tải là một vấn đề lớn nếu apply kiến trúc ở trên.
SCALE VỀ MẶT DATABASE VÀ SERVER KHI SỬ DỤNG CQRS
Khi sử dụng CQRS pattern, chúng ta có thể tách riêng hoàn toàn ra 2 server riêng biệt là Write side server và read side server. Và ứng với mỗi side, chúng ta sẽ có database riêng biệt.
SCALE ĐỘC LẬP VỚI NHAU NẾU LƯỢNG REQUEST TĂNG LÊN ĐỘT BIẾN
Bởi vì thông thường lượng request ở Read side chiếm phần lớn, nên bạn sẽ dễ dàng scale server (phần cứng hoặc instance nếu sử dụng cloud services) ở Read side. Ví dụ tăng cấu hình server lên hay tăng số lượng server lên. Hoặc sử dụng database chuyên dụng cho read data như Redis, mongoDB
Còn bên write side thì cũng có thể scale độc lập như vậy.
TỐI ƯU HOÁ PHẦN CỨNG CHO MỖI SERVER
Chúng ta có thể lắp các loại ổ cứng, ram chuyên cho đọc hay ghi tương ứng ở mỗi server read hay write (on-premise). Còn nếu chúng ta sử dụng cloud service có thể dễ dàng lựa chọn các service phù hợp cho mỗi side của ứng dụng.
SAU KHI SCALE XONG THÌ CHÚNG TA SẼ CÓ DESIGN SAU
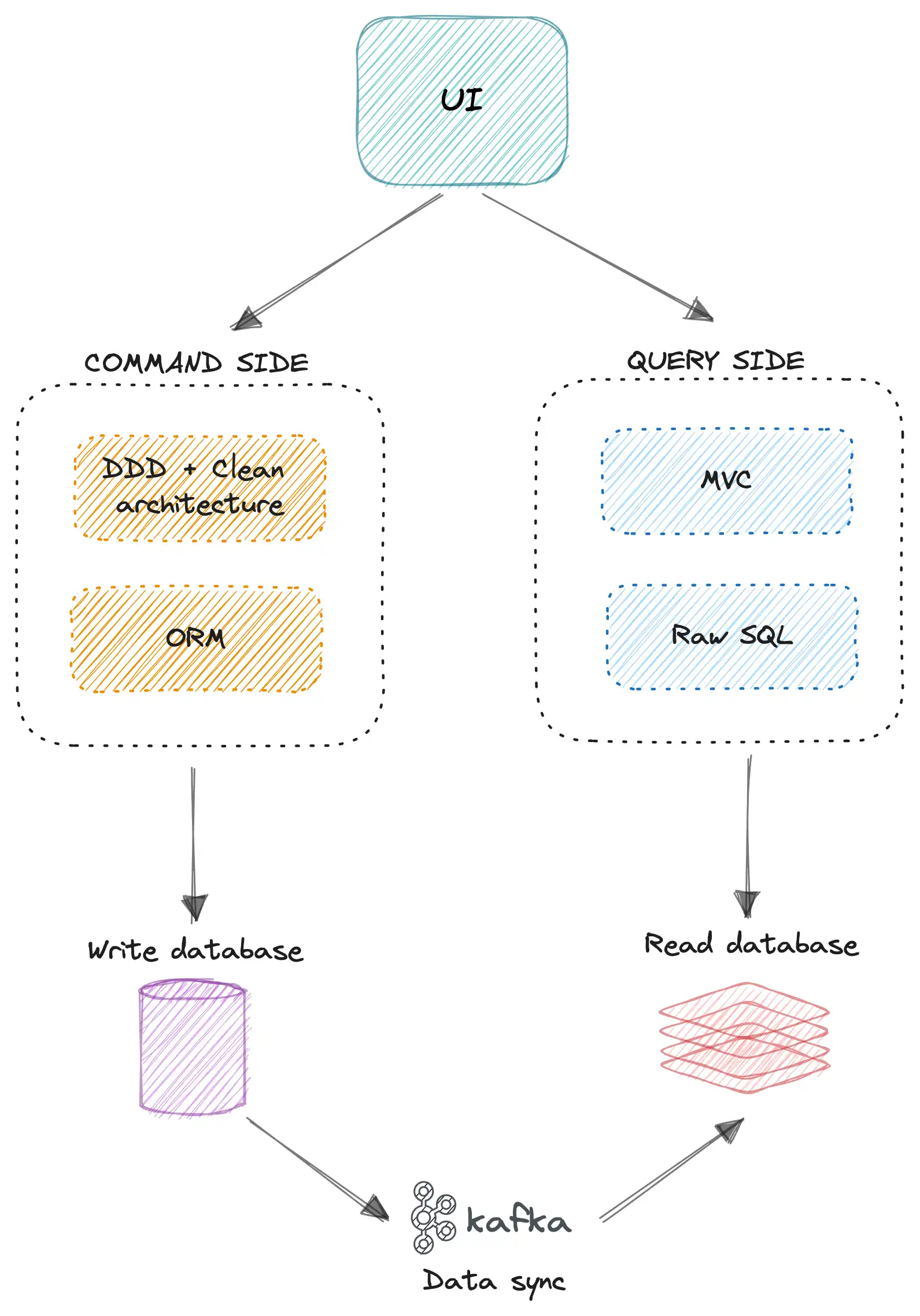
Ở hình trên mình đã dùng Kafka (một message queue) để có thể sync data bất đồng bộ từ write side sang read side.
Và ví dụ bên dưới sẽ cho các bạn thấy mình sẽ dễ dàng scale hệ thống như thế nào. Ở design dưới thì mình scale về database là chính.
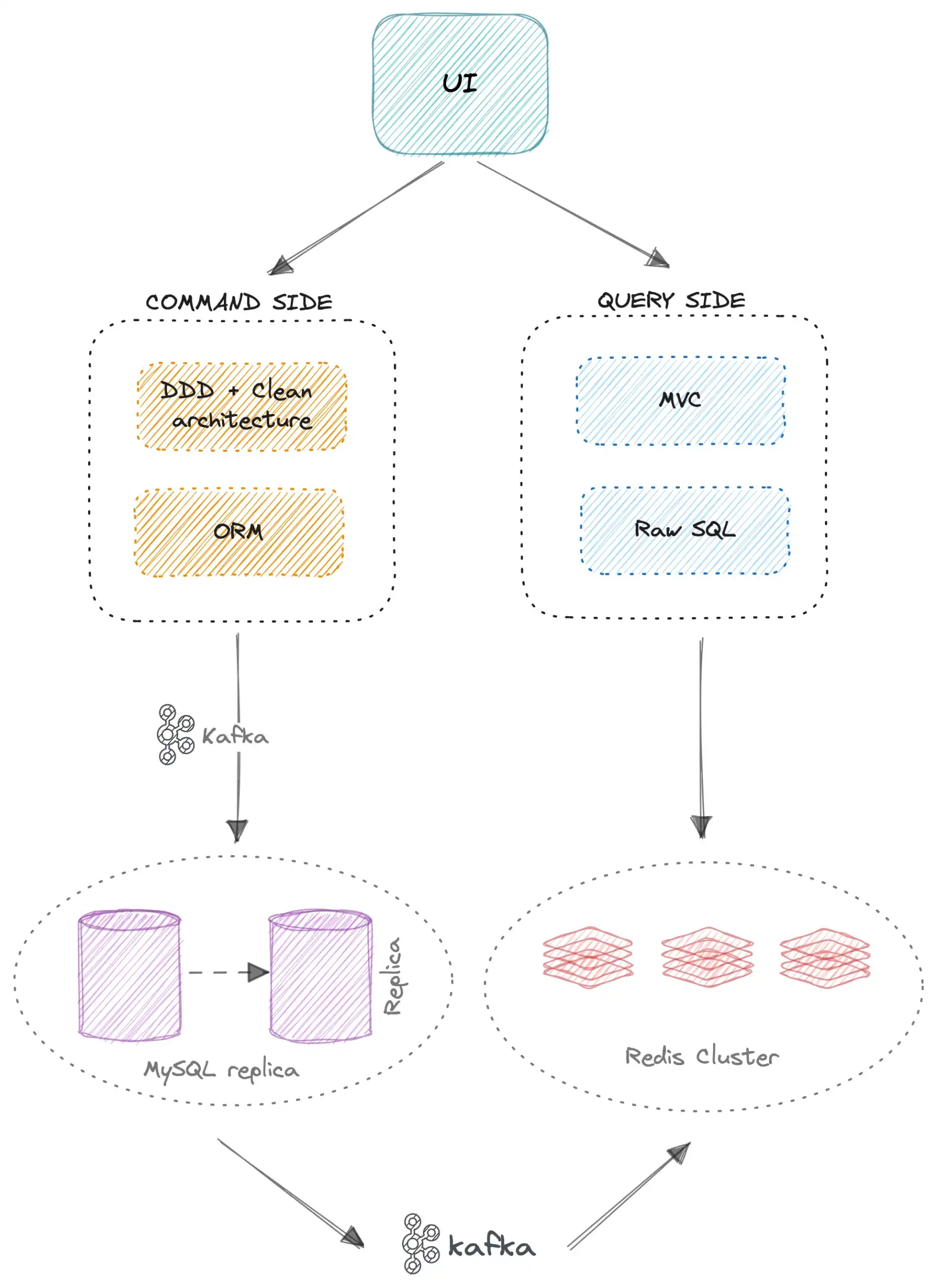
- Mình có design một message queue (mình dùng Kafka) ngay trước khi ghi dữ liệu vào write database. Bởi vì lý do là nếu chạy đồng bộ (sync) thì ngay write database sẽ dễ trở thành một nút thắt cổ chai khi lượng request write tăng đột biến.
- Ở write database thì mình dùng một Replica database. Và coi như là một backup trong trường hợp server bị chết.
- Một message queue để đồng bộ dữ liệu từ write database sang read database.
- Ở read database nếu lượng request quá nhiều và dữ liệu quá lớn. Thì mình có thể design nó thành một hệ thống database distributed (phân tán) để chịu tải tốt hơn và high availability hơn.
- Ngoài ra chúng ta cũng có thể sử dụng K8S auto scaling instance cho ứng dụng của mình đặc biệt bên read side cho hệ thống ở trên.
Tới đây thì chúng ta đã biết CQRS là cái gì rồi. CQRS hay như thế đấy! Nhưng vẫn sẽ có một vài điểm đánh đổi (trade-off). Chúng ta cùng tìm hiểu tiếp.
VẤN ĐỀ KHI ÁP DỤNG CQRS
TÍNH NHẤT QUÁN VỀ DỮ LIỆU (DATA CONSISTENCY)
Đây chính là một loại đánh đổi (trade-off) khi chúng ta triển khai các hệ thống lớn.
Đây có thể xem là vấn đề lớn nhất khi áp dụng CQRS. Hay những pattern khác mà sử dụng event driven architecture (sử dụng Kafka đó bạn). Bởi vì data được sync bất đồng bộ từ write side lên read side nên dữ liệu sẽ không nhất quán (inconsistency).
Khi dữ liệu được tạo hoặc update bên write side. Thì đôi khi phải mất một khoảng thời gian nhất định thì dữ liệu đó mới sync qua được read side. Nhất là trong những lúc cao điểm, request tăng cao dẫn tới server chịu tải nhiều hơn.
BÂY GIỜ CHÚNG TA SẼ NÓI MỘT CHÚT VỀ TRADE-OFF
Nếu chúng ta muốn dữ liệu consistency (nhất quán). Nghĩa là dữ liệu bên write side update sao thì tất cả các request bên read side luôn trả về dữ liệu mới nhất. Thì ở đây chúng ta có thể sử dụng cơ chế sync (đồng bộ) thay vì async (bất đồng bộ). Ví dụ như sử dụng Rest API để sync dữ liệu luôn. Như vậy chúng ta sẽ có dữ liệu consistency. Nhưng chúng ta sẽ phải đánh đổi thời gian response ở write side. Và khi lượng request tăng cao có thể dẫn tới server quá tải và không thể handle request. Dẫn tới tính availability sẽ thấp xuống.
Và đương nhiên ngược lại, nếu chúng ta muốn availability cao thì phải đánh đổi với consistency.
Tùy vào business của hệ thống mà chúng ta (là những engineer) lựa chọn về việc đánh đổi khi triển khai hệ thống lớn.
Đối với một số hệ thống không cần yêu cầu về tính chất consistency tuyệt đối như báo điện tử (24h, VnExpress), media, …. Chúng ta có thể đặt tính availability lên trên consistency và có thể sử dụng design ở hình trên. Lúc này chúng ta sẽ có khái niệm eventual consistency (nghĩa là không hoàn toàn nhất quán).
PHỨC TẠP HOÁ VÀ CHI PHÍ CAO
Câu mình muốn nói là: Không phải lúc nào cũng apply CQRS nếu không muốn tăng độ phức tạp của project.
Các bạn có thể thấy những hình ở trên, để triển khai một hệ thống lớn áp dụng CQRS và event driven architecture (và những pattern khác). Thì mọi thứ sẽ phức tạp hơn rất nhiều từ việc nhân sự, đội ngũ, đến cách tổ chức code. Và đặc biệt là hệ thống server sẽ nhiều hơn.
Hệ thống server nhiều (service nhiều) sẽ đi kèm với độ phức tạp cũng tăng lên rất nhiều. Như khi chúng ta monitor, xử lý, khôi phục hệ thống khi lỗi, … Vâng, và đó cũng là một kiểu trade-off cho chúng ta.
Thiết kệ hệ thống lớn, chúng ta phải đưa ra lựa chọn!
KẾT LUẬN
Trong hành trình khám phá CQRS là gì này, chúng ta đã thấy những ưu và nhược điểm của mô hình này. CQRS không phải là một giải pháp đối với tất cả các ứng dụng. Nhưng nó có thể là lựa chọn mạnh mẽ cho những ứng dụng đòi hỏi hiệu suất cao và tính mở rộng.
Nhớ rằng, quá trình triển khai CQRS có thể phức tạp, nhưng nếu được thực hiện đúng cách. Nó có thể đem lại lợi ích lâu dài cho sự phát triển và bảo trì của ứng dụng. Hãy cân nhắc kỹ lưỡng và kiểm soát mỗi quyết định để đảm bảo rằng CQRS phản ánh đúng nhu cầu của dự án của bạn.
Chúc các bạn thành công trong việc xây dựng các hệ thống mạnh mẽ và linh hoạt!
Các bạn có thể tham khảo source code mình có demo một chút về CQRS là cái gì ở link sau: lenhatthanh20/news-website (github.com)
À còn một ý nữa. Khi bạn search những bài viết kiểu CQRS là gì trên google. Thì nó ra khá nhiều các title như Event sourcing, Event Driven Architecture, DDD … Các bạn có thời gian thì tìm hiểu thêm nha. Mình chỉ muốn trình bày only CQRS là cái gì trong bài viết này thôi.